
Agile Estimation
Written by Ned Kremic

Estimation is an essential part of any project management activity.
Agile is no different, we have to estimate for scoping, scheduling and budgeting.
However the planning and estimation between traditional waterfall process based on PMI PMBOK and Agile approach are quite different.
Why?
It is beyond the scope of this article to explore all details, however the most important high-level aspects will be emphasized.
Just to clarify, this article is not about how the agile estimation should be done. Agile is empirical process where you should explore and refine through retrospectives what best fits your organization.
However this is "typical" way how many Scrum projects do estimation, and has been proven on a large number of small, medium, large and mega-sized projects.
Also this article is based on training that I provide to new agile teams, and results are that those teams are getting very proficient in estimating the epics, user stories and tasks immediately after the training. Even more, after few estimation sessions, the accuracy of our estimates have been remarkable.
I hope that this article will help you on your journey to do better and more accurate estimates.
Traditional process is aiming to produce detail requirements document for a given scope. Based on those requirements, the team will create the work break down structure (WBS) and define the low level tasks and activities.
Each activity will be estimated and scheduled (Ghant Chart), hence the schedule and project plan will be produced. If the requirements are sufficiently detailed and the detail design specification is drafted, based on PMI cone of uncertainty the accuracy should be -10 to +15%.
However, 40+ years of historical data have taught us that:
- Scope is never static. It always changes, no matter how much effort we put in defining the requirements.
- Scheduling 6+ months project is never accurate, no matter how much effort we put in defining the fine grain tasks and activities
- Risk and risk mitigation strategies are almost impossible to accurately calculate into the Scope, Schedule and Budget
To better address those issues, the agile has generally adopted a different way of estimation.
What do we Need to Estimate?
There are following artifacts in a Scrum process:
-
Product Backlog
The product backlog is a collection of user stories, themes and epics.
-
User Stories
The most important stories are on the top of the product backlog scheduled to be implemented first in the next few iterations. Those are granular user stories, where each story will deliver the tangible value to the product owner.
-
Themes
Further down the product backlog stack are the themes. Themes are collection of several related user stories. Those user stories must be further groomed before they are ready for implementation.
-
Epics
At the bottom of the product backlog are the epics. Epic as its name implies is a collection of several to over a hundred user stories.

Iteration (Sprint) Backlog
The iteration backlog is a collection of user stories from the top of the product backlog that product owner has indicated as the most important ones, and that the team has committed to implement, test and deliver in a given iteration.

Each user story that will be implemented in a current iterations, will be further divided into tasks. Task is the smallest unit of work that will be defined. All team members are already familiar with the tasks, as they are common both in traditional projects (tasks in Gantt chart) as well as in Scrum. The difference is that agile teams are defining the tasks only when they are needed, that is during the iteration (sprint) planning session, not 6 months ahead so that project manager could put them into the Gantt chart (MS Project, Primavera etc...), and there is a good reason for that, that you will learn shortly.
Most of examples in this article will be non-software ones, as software is intangible and very difficult to visualize. I will mostly use concrete estimation examples from the real world, first linear so that you could grasp the concept easily, than more complex two or three dimensional ones. Once you get clear understanding how it works, we will move to software examples which are intangible (have no dimensions associated with it)
Why separating User Stories and Tasks estimation?
Agile teams separate estimates of size from estimates of duration.

What is size and what is duration?
Let's say my our objective is to travel from Toronto to Montreal. The first thing I am going to do is ask somebody who has already travelled, how long did it take. And just to be sure, I will verify with another person her experience to get more accurate estimate.
Ned: "I want to travel to Montreal. Rob how long did it take you to get there?"
Rob: "5 hrs"
Ned: "Mary you were in Montreal last week on a business trip. How long did it take you to get there?"
Mary: "1 hr!"
Same distance (size), so different durations ???

The picture says it all!
We can relate this example to any software project. For the same scope (if we can size it) we may get completely different answers, based on the technology used to implement it (.NET WebServices, Oracle WebLogic), development tools, domain expertise and the skill-set of developers.
Even in this simple, linear example, travel from Toronto to Montreal, there are many variables that may change duration 700% percent for the same size!
- Different vehicle (technology), airplane, truck, bus, car.
- Familiarity with the road (domain expertise)
- Driving ability (proficiency). For instance, Michael Schumacher probably can drive this trip in 3.5 hrs, my mother in 7hrs
Hence, if we could somehow size the software project, we would be better positioned to derive the duration when we know all variables, such as technology, proficiency, expertise and experience of the team members.
Does it make sense to estimate the duration of each task in traditional project that will last 6+ months, if we may change technology during the project, and people who have originally estimated it may have already left the project or moved to another one?!
Absolute Size
500 km distance between Toronto and Montreal is an "absolute size".
1kg of apples or bananas is an "absolute size"
In following diagram, we will measure the "absolute size" of an apple and a banana.

Software is "intangible". Is is possible to find the "absolute size" of it?
Well, the answer is yes, and it could be done with Function Point Analysis (FPA).
Function Point Analysis claims, that regardless of technology or programming language used, proficiency and expertise of developers, two or more certified FPA analysts would estimate the same project within the reasonable margin of error!
That is very encouraging claim! Even more, as of 2012, there are five recognized ISO standards for functionally sizing software.
However FPA requires a detailed requirements.
In Agile, user stories are intentionally vague, therefore FPA is not good match for them.
What else could we use, if FPA will not work for most agile projects?
How about relative sizing?
Relative Size
If we put a mellon or an apple on the scale, we will measure their "absolute sizes", that is their weight exactly in kilograms.
However, if we just want to compare which one is heavier, we can put them on the balance scale. We call it relative sizing, comparing one to another.

The best way to explain relative sizing is to go back to our example, trip from Toronto to Montreal.
This time we have non-scaled map, and we don't know the distance from those two cities. World "relative" implies that its size is relative to something else. Therefore we have to add more trips into our backlog in order to do relative estimation.
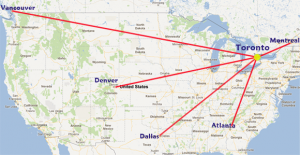
So, if our backlog consist of the following trips:
- Toronto - Montreal
- Toronto - Atlanta
- Toronto - Denver
- Toronto - Dallas
- Toronto - Vancouver
and as mentioned we don't have scale on the map, what can we do? Sure we can do relative sizes and compare them.
So if the shortest trip is between Toronto and Montreal, lets say it has size of 1.
Let's estimate Toronto - Denver. Eyeballing, that line is approximately three times as long as Toronto to Montreal. Hence we will size it 3.
Toronto - Atlanta. At this point we will use so called "triangulation". We already have 1 and 3 point lines, so Atlanta is longer than Toronto - Montreal, but shorter than Toronto - Denver. Let's size it as 2.
The longest one is Toronto - Vancouver. Eyeballing will tell us that is it roughly around 5.
Later, the new travel destination emerged. Toronto-Dallas. Again, using the triangulation we can easily say that this line is approximately as long as Toronto-Denver (3), and for sure longer than Toronto-Atlanta (2), but shorter than Toronto-Vancouver (5)
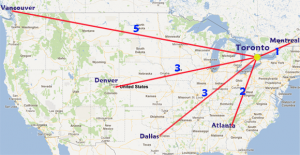
| Travel Distances | Distance Points |
| Toronto - Montreal | 1 |
| Toronto - Atlanta | 2 |
| Toronto - Denver | 3 |
| Toronto - Dallas | 3 |
| Toronto - Vancouver | 5 |
Great. We have relative sizes and now what. How can we use it to estimate how long will it take us complete this project and properly schedule our trips?
As mentioned earlier, we don't estimate time, we derive it based on our "real velocity". In this example, our velocity is number of hours to travel 1 linear-distance point.
As we have never before undertook such project, and we don't know the speed of the aircraft, or absolute (real) distance between those cities, we will start by roughly estimating that our velocity will be 2hrs per 1 point.
Hence our estimation table may be:
| Travel Distances | Distance Points | Estimated Duration |
| Toronto - Montreal | 1 | 2 hrs |
| Toronto - Atlanta | 2 | 4 hrs |
| Toronto - Denver | 3 | 6 hrs |
| Toronto - Dallas | 3 | 6 hrs |
| Toronto - Vancouver | 5 | 10 hrs |
Now, in our first iteration we will travel from Toronto to Montreal, and will soon discover that it actually took us only 1 hr to span the distance of 1 point!
Do we need to re-estimate? Absolutely not. The relative sizes haven't changed. We have only determined our real velocity, and we have determined it soon, which is the real strength of this kind of estimation.
So if we correct the schedule based on our discovered velocity, we will come up with schedule like this.
Please keep in mind that a schedule is "derived" based on the "real velocity". It is not estimated!
| Travel Distances | Distance Points | Estimated Duration |
| Toronto - Montreal | 1 | 1 hrs |
| Toronto - Atlanta | 2 | 2 hrs |
| Toronto - Denver | 3 | 3 hrs |
| Toronto - Dallas | 3 | 3 hrs |
| Toronto - Vancouver | 5 | 5 hrs |
Of course in the real world, the velocity will fluctuate. However we will always estimate based on the average of the last three velocities which will give us the most accurate schedule for the current state of our resources.
Therefore the actual velocity will correct the estimated duration.
The beauty of this is that estimating in "distance points" completely separates "estimate of size" from "estimate of duration".
Relative Size Advantage
Perhaps, the absolute size would be better, but clearly we cannot use it in most agile projects.
- Relative size can be used with "vaguely defined" user stories.
- Duration is not estimated, it is computed or derived based on estimated velocity for one iteration.
- Velocity corrects the estimation errors
- People are generally very good with relative estimates - it is easy
The Estimation Scale
The scale we used for our North American trips were good for short distances: 1,2,3,5,8
How to estimate long distances?
Is Toronto - New Delhi size 23 or 24?

- It doesn't make sense to be overly precise with the large sizes
- Difference of 1 between 1-2 is 100%
- Difference of 1 between 42-43 is around 2%
To address this issue, most agile estimation teams have decided to use modified Fibonacci sequence: 0,1,2,3,5,8,13,21,40,100
Sequence is intentionally not linear, and it says that there are so much unknown in 30 points user story, that it is probably better to size it with 40, and then "groom" and split into the smaller stories before implementing in a given iteration.
Estimation with Multiple Teams
It is important to note, that as we are talking about relative sizes, each estimation team will have different notion of their baseline. Therefore one team may estimate Toronto to Montreal to be 1 distance-point, while another team 100 distance-points, however the real schedule will always yield 1hr for that trip. So the team #1 will have velocity 1 distance-point/hr, while team #2 100 distance-points/hr.
With wide adoption of modified Fibonacci sequence, agile projects have started to narrow down their relative sizes.
If you are working on a large, multi-team project, in order to avoid different relative sizes for the user stories in the same backlog, the representatives from each team should form the estimation team. Than each team will pick from the same backlog and sizes will be in the same "units". Of course velocities between the teams may be different. And real, derived velocity provides great visibility into performance of each team.
If team #1 can drive consistently between Toronto and Montreal in 4 hrs, and team #2 in 6 hrs, obviously we see some serious performance issues here, as both of them are driving the same type of car!
The example explained in this picture, shows three cross-functional teams, each with five team members. Two members (e.g. Developer and Tester) from each team will join the estimation team. This way the estimation team will come with consolidated estimates, and later whichever team gets to work on the user story will have it sized also by representatives from its own team that agreed that the size is right. This way we can have one backlog for the entire project.
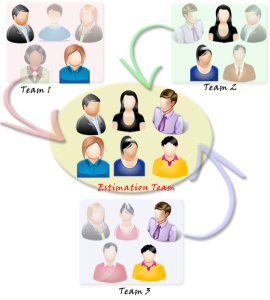
Estimation Effort
Novice estimators will have natural tendency to over-analyze the user stories in order to come with accurate estimates. Sometimes discussion may spill into the full-blown design session.
Our objective is not to come to the perfect and accurate estimate, rather to size the given user story based on some benchmark stories, using triangulation technique.
Back to our original example for the North American flights. There is no point in arguing too much about the distance between Toronto and Atlanta. Simply we had two previously estimated and maybe even proven (implemented) lines, Toronto-Montreal (1 distance-point) and Toronto-Denver (3 distance-points). Without much discussion we should realize that Toronto-Atlanta is somewhere between those two, hence 2 distance-points.
Please keep this in mind: No matter how much effort you put in estimate, an estimate is still an estimate!!!
No effort will give you 100% accuracy.
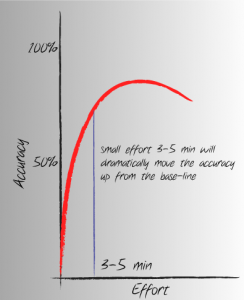

We use the following diagram and keep it handy during estimation session on the wall to remind the estimators about the following facts:
- Small effort will dramatically move the accuracy up from the base-line
- Within 3-5 min deliberation, you have a pretty good chance to be fairly accurate estimating relative size with triangulation technique. For help keep the poster of prior user stories (or picture of North America travel lines)
- Anything longer than that, will not produce more accurate estimate, and in fact the accuracy may go down due to over analyzing
- To keep focused and always aware of time limitation, the best approach is to use the 5 min sand-clock and keep it in a middle of the estimation table.
How to estimate size
We will need several stories for relative sizing
- Sort them: Small, Medium, Large (so called T-Shirt sizing)
- Pick the smallest one and size "2" (don't start from 1. There may be a smaller story down the road)
- Pick the next one and play the "Planning Poker"
- Pick another one, triangulate and play the "Planning Poker"
Planning Poker

Yes, sounds silly, but we do play poker and we play it "good". And even better our estimates are accurate!
The whole team participate. If there are multiple teams on the same project, select few representatives from each team, taking into account that you have cross-functional representation in your estimation team.
- Planning poker will size the user story (or trip distance in our example)
- Moderator (Product Owner or Scrum Master) reads the story.
- Team briefly discusses the story, and product owner provides the answers.
- Everyone silently selects a point card
- Team reveal all cards in unison.
At the beginning with inexperienced estimators, or on the new project when domain expertise is not established yet, you will have a wide-range.
Outliers, in our case estimators with min (3) and max (20) elaborate why their estimates are so different.
Team discuss again and re-vote
The goal is for estimators to converge on a single estimate. If they cannot, you should err on conservative side.
However our experience working on multiple projects is that teams will always converge after maximum 2-3 re-voting. Experienced and mature teams are very close to consensus after one, to maximum two voting cycles.
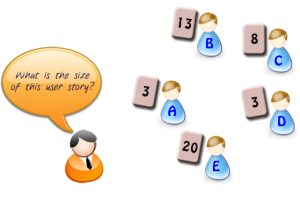
If you have wide range, such as this one 3 - 20, the reason is usually:
if the range is between developers, one (20) didn't know that functionality necessary to implement this story has already been done, is encapsulated in API and could be re-used.
Or, developer who has voted (3) is not domain expert and didn't know about complexity with interfacing with third-party system, regulatory issues etc.
Or, the difference is between developer and tester. The story is fairly simple to implement (3), however there are so many complex test scenarios, and the data must be mined in the backend DBs (20)
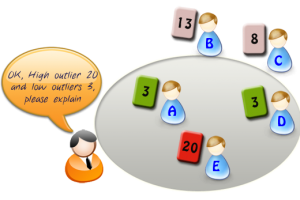
Usually, those undiscovered constraints will be acknowledged after the first voting round, and estimators will quickly converge.

Why Planning Poker Works
- Brings together multiple expert opinions to do estimating (The Delphi Technique)
- "The people most competent in solving the task should estimate it"
- Lively dialogue during planning poker
- Outlier estimators justify their estimates
- Averaging individual estimates lead to better results
- It's FUN!
Let's play the Planning Poker
As promised earlier, before we move to "intangible" software user stories, we have to practice what we have learned on something more complex than linear distance estimations.
Try to estimate the size of the fruits.

What do we size here, weight or volume? What units do we use?
This should be all agreed before we start estimation.
For this example, we will size based on fruit volume, and the units will be ... what else than the fruit-points!?
We will use the modified Fibonacci sequence (1,2,3,5,8,13...) and the real agile estimation cards. You can find it for free for your iPhone or Android phone.
You can try it on your own. Here is my estimate:
| Fruit | Fruit Points |
| Cherry | 1 |
| Plum | 5 |
| Apple | 12 |
| Banana | 12 |
| Melon | 40 |
| Watermelon | 100 |
Estimating User Stories
Now, after estimating in distance-points and fruit-points, we may be ready for the real thing. Estimating something that is not visible, not touchable, unit-less. software requirement - the user story!
In agile, we are using user stories as requirements. Why?
It is beyond this article to elaborate all advantages of the user stories, however in short "The user stories are natural way to explain what the user wants, and is easily understandable by all stakeholders"
Traditional requirements (IEEE 830 style "the system shall") have sent many software projects astray, because they focus their attention on checklist of requirements rather than on the user's goals.
Here is another "bit over exaggerated" example, however everybody who has worked on software projects before may closely relate to this:
IEEE 830 Traditional Software Requirements:
3.4) The product shall have a CPU
3.5) The product shall have a keyboard
3.6) The product shall have a screen
3.7) The product shall have a spell-checker
3.8) The product shall support POP3 protocol
3.9) The product shall support IMAP protocol
3.10) The product shall send an email when send command is executed

Same requirements, expressed as the user story:
"As a mobile phone user, I would like to send an email from my mobile phone"

I like even more Mike Cohn's blunt example, how far that may go:
IEEE 830 Traditional Software Requirements:
3.4) The product shall have a gasoline-powered engine.
3.5) The product shall have four wheels.
3.5.1) The product shall have a rubber tire mounted to each wheel.
3.6) The product shall have a steering wheel.
3.7) The product shall have a steel body.

Same requirements, expressed as the user story:
"The product makes it easy and fast for me to mow my lawn"

Practical Guide how to Estimate User Story
Estimating user stories is no different than estimating plane trips or estimating the size of the fruits. In essence it is done the same way, as explained in sections "How to estimate size" and "Planning Poker".
If you follow the suggestions outlined in this article, even your first estimation session will go relatively smoothly.
Usual mistakes the beginner teams are making, is to over analyze and break 5 min time-box. No need for that.
For the beginning, take the stories from the top of the product backlog that the Product Owner has identified as the most important ones and put them on the board. Or display them with projector if you are doing electronic version (e.g. Rally, IBM RTC, VersionOne or simply spread-sheet...).
They should be visible!
Size them based on T-Shirt sizes Small (S), Medium (M), Large (L) and Extra Large (XL)
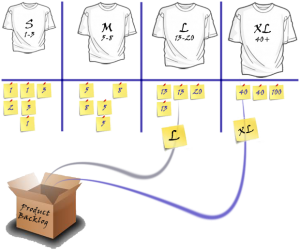
Pick the smallest one (everybody agrees that it is the smallest and easiest) and size it as 2. Yes 2 not 1.
There may be, and will be a story down the road that will be smaller than this one, and you don't want to go sub 1.
This is your starting point. The first story that you have sized with "2" will be your benchmark.
Every other story is relative to this one!
Take another story from the Small (S) size bucket, and estimate it relative to the first one.
From here, all other stories will be estimated using the "triangulation" technique explained before.
If your relative size ratio is correct, then you will not need to re-estimate.
Remember, you are not estimating duration, just the size. Duration will be derived and always corrected with velocity. (See example estimating flight times between North American cities in this article).
It is important to remember for each estimation session, always put on the board all the stories that you would like to estimate.
On the side of the board, put the sample representative of the already estimated and implemented user stories, one of more from each group 1,2,3,5,8
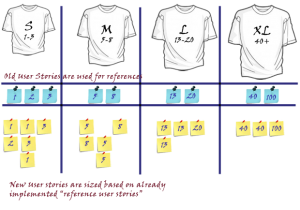
When team discuss this story, they can "triangulate" or correlate with some of already implemented stories on the board.

Try to keep the user stories that you are going to implement in this range (1,2,3,5,8).
Larger stories 13, 20 are already Themes and should be further groomed and split in the smaller ones. Sometimes it will be difficult, but there is high chance that your team will not be able to complete the 13 point story in one iteration, and will carry over to the next one. This is bad practice.
Make the culture in your organization that "carry over stories" is a bad practice.
When team commits to deliver, than it should deliver. And your best chance to deliver is with 1,2,3,5 user point stories.
There are many reasons why the user stories, even the small ones may not be delivered in one iteration, and this is the topic for another article (dependencies on other teams, vendors or companies. Environmental issues etc)
But never carry over the user story to the next iteration when the entire development and testing is in your team control!
After you have done this session several times, this estimation process will become the second nature for your teams.
You may expect:
- The consensus between cross-functional estimation members (SA, UX, Developers, QA) will be achieved in most cases even in the first round of user story estimation. The span will be for instance one magnitude low or high (e.g: 2,3,5), not (1,3,13)
- If the consensus was not reached in a first round, because there was different understanding of the story, or certain members were not aware that the functionality already exist, (1, 5, 13, 20) the consensus will be reached without re-voting (5,5,5,5)
- The accuracy your team will achieve will be amazing. You will be able to measure accuracy with the number of hours that the teams are spending implementing the story of the certain size. Of course correlation is not linear, but if one story is 3 story points and your team spent 30 hrs to complete it, the next user story of the same size (3 sp) which means has the same complexity, cannot take 5 hrs or 120 hrs to complete. It should be somewhere around 20 - 40 hrs.
The objective of this article was to introduce you to real-life examples of agile estimations that yielded fantastic results in several organizations and many more teams. With simple training outlined here, we managed to get agile teams to estimate effectively, very accurately that helped teams commit and deliver based on those commitments, as well as to management to do proper planning and budgeting.
As I have already mentioned, the agile estimation is just one part of the agile planning, and other topics that use outcomes of agile estimation will be covered in subsequent articles.
Wish you success with your estimation!